JavaScript SEO – Crawling, Indexing & Rendering
Dieser Artikel erschien im Original auf dem .kloos Blog
JavaScript und Suchmaschinenoptimierung waren sich lange Spinne Feind. Der Grund dafür war einfach: Google und andere Suchmaschinen konnten JavaScript nicht ausführen und daher Inhalte, die per JavaScript geladen oder nachgeladen wurden, auch nicht finden.
Mittlerweile aber werden JavaScript basierte Frameworks wie Angular, ReactJS, ember, vueJS usw. immer beliebter. Auf diese Weise können Programmierer Webseiten viel schneller und einfacher umsetzen. Große Entwickler-Communities sorgen dafür, dass beliebte Funktionen und wiederkehrende Muster bereits fertig bereitstehen und auch kontinuierlich weiterentwickelt werden.
JavaScript is here to stay
Mit der wachsenden Beliebtheit von JavaScript Frameworks kommt man auch als SEO nicht mehr darum herum, sich den Kopf darüber zu zerbrechen, wie man solche Seiten für Googlebot & Co zugänglich macht.
Um zu verstehen, wo die Probleme bei JavaScript Websites aus SEO Perspektive liegen, muss man zunächst einmal die grundsätzliche Funktion solcher JavaScript Frameworks verstehen und zum anderen das Konzept, wie Google Seiten crawled, indexiert und rankt kennen.
JavaScript Single Page Web Apps & SEO
Beim Aufruf einer „normalen“ Seite passiert – sehr vereinfacht
ausgedrückt – folgendes: Der Client, also im Normalfall der Browser des
Users, fragt beim Server nach dem HTML Quellcode, lädt diesen vom Server
und fragt dann nach allen weiteren Ressourcen (CSS Dateien, JS, …), die
in diesem HTML Dokument gelistet werden, um dann die Seite anzuzeigen.
Ob das HTML Dokument jetzt „fertig“ am Server liegt, oder dynamisch z.B.
mit PHP serverseitig zusammengestellt wird, ist dabei gleich.
Grundsätzlich sind Struktur und Inhalte aber jedenfalls schon im HTML
Quellcode enthalten. Klickt sich der User durch die Seite wird bei jedem
Seitenaufruf wieder eine HTML-Datei vom Server geladen.
Bei JavaScript Frameworks, wie Angular, React & Co ist diese Funktionsweise ein wenig anders. Sie basieren auf dem Single Page App Modell. Das heißt – auch wieder sehr grob skizziert – folgendes: Beim ersten Seitenaufruf wird zwar auch ein HTML-File geladen, das auch auf CSS und JS-Ressourcen verweist. In dieser HTML-Datei ist aber keinerlei Inhalt zu finden. Dieser wird ausschließlich per JavaScript hinzugefügt.
Als Beispiel kann man sich die Default App von Googles Angular Framework ansehen. Auf der „Welcome“ Seite sieht der User im Browser einen einfachen Header, ein Logo, sowie einen Content Bereich mit drei Links. Sieht man sich aber den HTML Code der Seite an, findet sich im, also dem sichtbaren Bereich, lediglich ein leeres Tag sowie fünf Scripte:
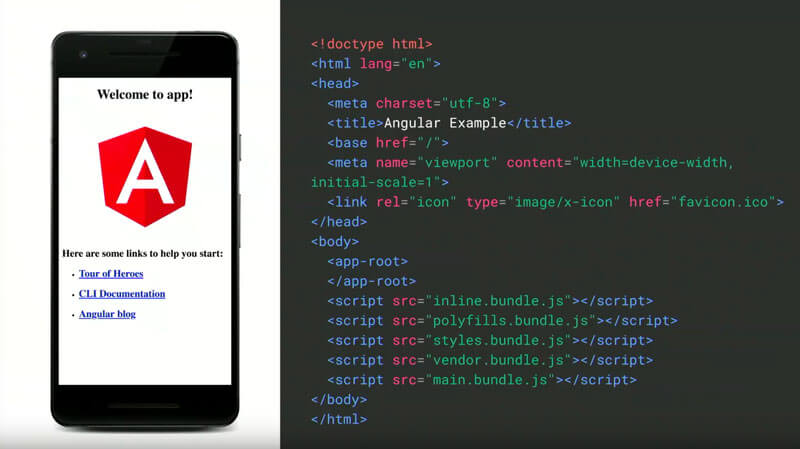
Welche Inhalte angezeigt werden und wie die Seite dann aussieht, wird mit den Daten die das JavaScript übergibt erst im Browser „errechnet“. Statt ein fertiges HTML-Dokument auszuliefern, entsteht der HMTL-Quellcode bei diesem Client-Side Rendering erst im Browser. Durch JavaScript lässt sich in Folge über das DOM (Document Object Model) das HTML dynamisch verändern, ohne dass ganze Seiten neu geladen werden müssen. Statt bei jeder Interaktion immer eine neue HTML Datei zu laden, werden nur noch die benötigten Informationen nachgeladen.
Wird der gesamte Inhalt einer Seite aber auf diese Weise geladen, sieht ein Suchmaschinen-Crawler, der nur den HTML-Code einer Seite ausliest, nichts. Wovon diese Seite handelt und auf welche anderen Seiten sie verlinkt, kann die Suchmaschine nicht nachvollziehen. Wie lösen Suchmaschinen das Problem, bzw. wie können wir als SEOs helfen, das Problem zu lösen?
Dazu müssen wir zunächst den Prozess verstehen, wie Google Webseiten findet und wie die Suchmaschine versteht, wovon eine Seite handelt.
Crawling, Indexing… und Rendering
Bis Google seine selbstgesetzte Aufgabe erfüllen kann – dem User das relevanteste Ergebnis anzuzeigen – sind verschiedene Schritte notwendig. Vor allem geht es darum Webseiten zu finden und deren Inhalt korrekt zu interpretieren. Erst dann können die so in Googles Index gelangten Seiten gerankt werden.
Dazu zieht Googlebot, also der Crawler, durch das Web, indem er
Hyperlinks folgt. Seine Aufgabe ist das Auffinden aller URLs. Weil –
zumindest theoretisch – jede URL im Web auf irgendeine Weise miteinander
verlinkt ist, kommt der Bot auch irgendwann auf jede einzelne URL.
Der Crawler hat eine einfache Parser-Funktion, um den HTML-Quellcode
auszulesen und ein paar grundlegende Dinge herauszuziehen. Etwa Robots
Meta-Anweisungen oder Canonical Tags, vor allem aber Links, über die er
auf weitere Seiten kommt. Außerdem gibt der Crawler jede gefundene und
indexierbare Seite und die wichtigsten Ressourcen (CSS, Bilder,..) an
den Indexer weiter. Dieser Teil des Google-Algorithmus versucht nun den
Inhalt der Seite zu verstehen.
Und in diesem Prozess taucht jetzt ein Problem bei JavaScript basierten Seiten auf. Würden Crawler und Indexer lediglich das geladene HTML-Dokument verarbeiten wären alle Seiten relativ leer. Damit Google das sieht, was der User sieht, muss daher der Indexer nun auch die Arbeit des Browsers übernehmen und die Seite rendern. Erst dann kann der Indexer den Inhalt verarbeiten. Und auch erst dann werden weitere Links “sichtbar”, die der Indexer wieder an den Crawler zurückgeben muss, damit dieser auf weitere Seiten kommt.
Zwischenfazit: Zwischen Crawlen und Indexieren muss eine Seite durch den Algorithmus nunmehr auch gerendert werden.
Können Suchmaschinen JavaScript rendern?
Google sagt seit 2014 von sich, dass der Google Bot mittlerweile JavaScript so gut rendern kann, wie ein moderner Browser. Seit Dezember 2017 ist man sich sogar so sicher, dass der Googlebot dem alten AJAX Crawling Schema nun nicht mehr folgen wird. Tatsächlich wissen wir, dass der Indexer einen Web Rendering Service (WRS) nutzt, der auf Google Chrome Version 41 (ein doch schon älterer Browser!) basiert. Voraussetzung dafür ist, dass keinerlei JavaScript und CSS Ressourcen durch die robots.txt Datei blockiert werden.
Um herauszufinden, wie Google eine JS basierte Website rendert, kann man auf die „Abruf wie durch Google“ (Fetch as Google) Funktion in der Search Console zurückgreifen. Hier sieht man einerseits, wie Google die Seite tatsächlich rendert, andererseits kann man auch den Quellcode einsehen.
Trotzdem tauchen immer wieder Berichte, Tests und Experimente auf, die vermuten lassen, dass Google JavaScript Applikationen doch noch nicht so gut versteht. Dazu kommt, dass schon kleine Fehler im JavaScript dazu führen können, das Google Inhalte nicht mehr sehen kann. Das mussten auch die Hauptentwickler von Angular feststellen, als die angular.io Website zwischenzeitlich aus dem Google-Index fiel. Zur Info: Angular wurde von Google selbst entwickelt 😉
Crawler anderer Suchmaschinen sowie Bots sozialer Netzwerke oder Messaging Services, die auf Seiten zugreifen um z.B. die Vorschaubox dazustellen, tun sich mit JavaScript aber immer noch sehr schwer und können solche Seiten meist (noch) nicht rendern.
Zwischenfazit: Google kann wohl JavaScript meist rendern, andere Bots tun sich sehr schwer.
Server Side Rendering!
Dazu kommt die Tatsache, dass auch wenn GoogleBot anscheinend in der Lage ist Angular, React & Co clientseitig zu rendern, JavaScript den Suchmaschinen das Leben deutlich schwerer macht! Denn Rendering braucht enorme Ressourcen. Dadurch wird der an sich recht reinfache Prozess des Crawlens und Indexierens enorm aufwendig und ineffizient. Wie John Müller und Tom Greenway in einem Vortag auf der Google I/O `18 bestätigen, kann sich im Crawl- und Indexierungsprozess das Rendering solange verzögert, bis entsprechende Ressourcen dafür frei sind.
Ganz abgesehen von den Problemen der Bots kann client-seitiges Rendering auch für User Nachteile mit sich bringen. Zumindest der Initial Page Load, also das Laden der ersten Seite, dauert in der Regel deutlich länger, weil das Rendering komplett vom Client übernommen werden muss. Zusätzlich hängt die Ladezeit von der Qualität und Rechenleistung des jeweiligen Endgeräts ab.
Deshalb lautet das Zauberwort um JavaScript Frameworks SEO tauglich zu machen: Server-Side-Rendering. Statt den HMTL-Code erst auf Client-Seite errechnen zu lassen, wird die Seite schon serverseitig „vor-gerendert“ (pre-rendering) und fertig ausgeliefert. Dazu gibt es verschiedene Lösungen, die PhantomJS, headless Chrome oder einen anderen headless Browser nutzen, um die Seiten bereits auf dem Server zu rendern.
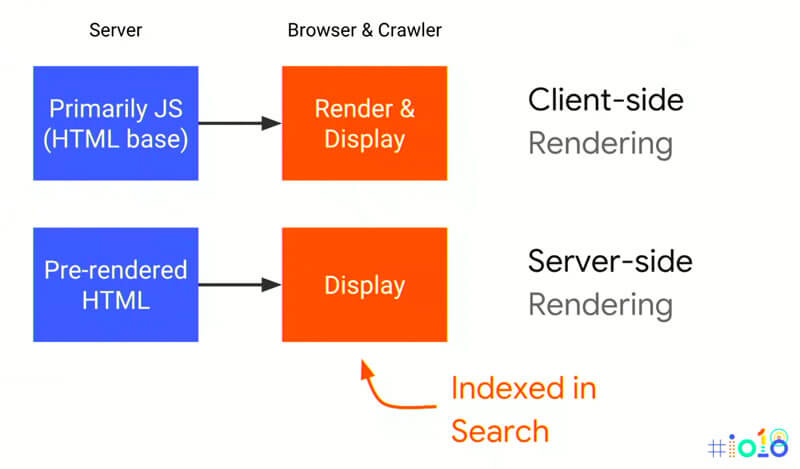
Nun gibt es aber mehrere Möglichkeiten, wann und wie Browsern (also normalen Usern) und Crawlern serverseitig vorgerenderte Seiten ausgespielt werden sollen.
1. Server-Side Rendering für Alle
Sowohl Browser als auch Crawler bekommen direkt das serverseitig vorgerenderte HTML ausgespielt. Alles JavaScript das nötig ist um die Seite grundsätzlich zu rendern läuft bereits auf dem Server. Client-seitig wird nur noch JavaScript ausgeführt, das von Nutzer-Interaktionen her rührt. Große Erfolge mit dieser Technik verbuchte Netflix, die durch die Umstellung auf server-seitiges Rendering die Ladezeiten der Netflix Seite sich um 50% verbessert konnten:
2. Dynamic Rendering
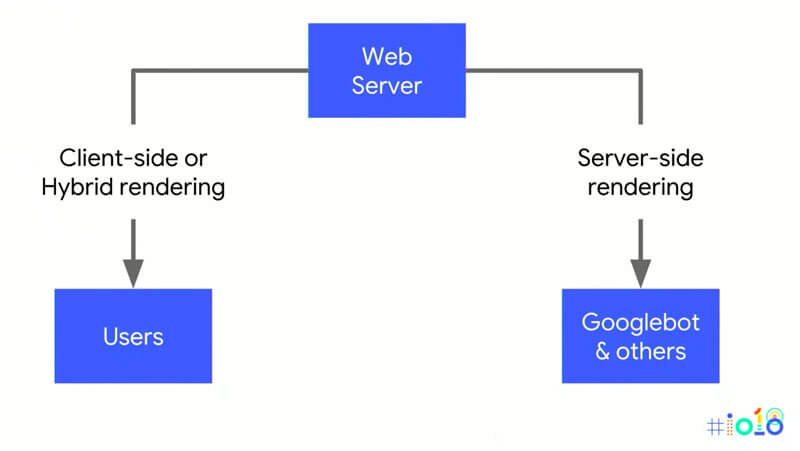
Bei dem Modell, dass Google „Dynamic Rendering“ nennt wird zwischen Browser und Crawler unterschieden. Während ein normaler Browser die JS Version der Seite ausgeliefert bekommt und diese clientseitig rendern muss, bekommen Crawler eine pre-rendered Version.
Dabei braucht es eine Middleware, die unterscheidet ob der Zugriff von einem normalen Browser oder eben einem Bot kommt. Hier wird einfach der User-Agent ausgelesen und gegebenenfalls auch die IP-Adresse verifiziert, von der ein Bot üblicherweise zugreift. Dazu erwähnt John Müller im Google I/O `18 Talk auch, dass diese Variante nicht als Cloaking gewertet wird.
3. Hybrid Rendering (Isomorphic Rendering)
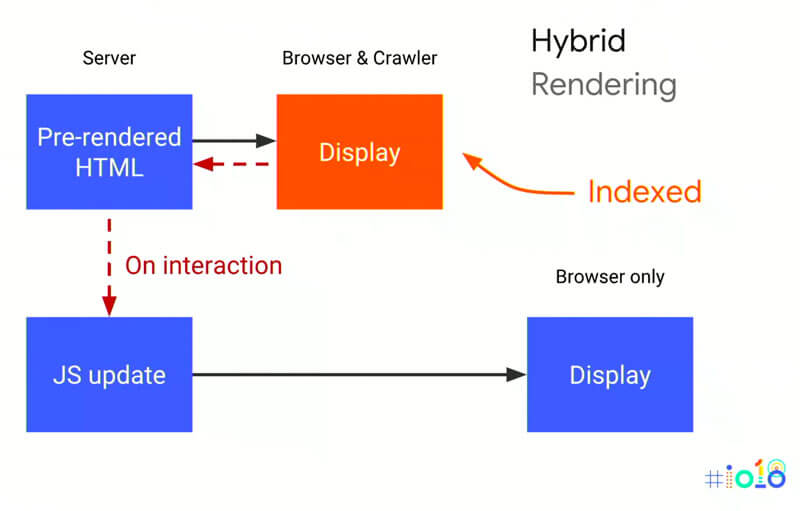
Google empfiehlt eine Hybrid Rendering Lösung, bei der sowohl normale User, als auch Suchmaschinen eine vorgerenderte Version der Seite ausgeliefert bekommen. Erst wenn der User beginnt mit der Seite zu interagieren, beginnt das JavaScript über das DOM den Quellcode zu verändern. Teilweise wird JS also bereits auf dem Server ausgeführt, für weitere Aktionen wird JS erst clientseitig ausgeführt.
Für das Angular Framework gibt es aber mit Angular Universal schon ein Modul, das ein solches Setup erleichtern soll. Trotzdem scheint es aber sehr aufwendig zu sein ein solches Setup sauber aufzusetzen.
Bekommt Google Bot die richtige Version?
Um zu testen, ob Google nun eine pre-rendered Version der Seite ausgeliefert bekommt, kann man wieder auf die „Fetch as Google“ Funktion in der Search Console zurückgreifen und sich den Quellcode ansehen. Der Googlebot sollte dann den komplett gerenderten HTML Code sehen, während im Browser der minimalistische HTML Quellcode der JS Version zu sein scheint. Zwei weitere Tools, um zu sehen welche Source der Googlebot zu sehen bekommt, sind der Mobile-First Test, für die mobile Seiten und der Rich Results Test für Desktop Ansicht.
Natürlich kann man auch andere Tools einsetzen, wie den SEO Crawler Screaming Frog (der auch JavaScript Rendering beherrscht und man sich Original und Rendert HTML ausgeben lassen kann) oder SEO Online Tools wie das Technical SEO Fetch & Render Tool von Merkle.
Bildnachweis: Alle Bilder sind Screenshots aus dem Vortrag von John Müller und Tom Greenway auf der Google I/O `18,